人工智能算力网络面世:多模态大模型已成大势所趋
文 | 曾响铃
来源 | 科技向令说
用文字描述“一个女人打着红色的雨伞在路上走”,系统呈现出一张唯美的街拍;
有一张飞机起飞的照片,想配上一段适合的声音,上传图片后,一段发动机呼啸声的音频播放出来;
把淅淅沥沥的下雨声导入进去,江南水乡老宅的氤氲雨景图展现在了眼前……
这些,是已经实现了的多模态AI应用,横贯文字、图像、语音,在初级应用功能上就已经展现出相比单模态更智能、更自然、更多样化的魅力,其前景被普遍关注,只不过很长一段时间以来,多模态的发展速度一直不算快。
现在,事情正在发生变化。
在华为全联接2021期间,中国科学技术信息研究所、AITISA(新一代人工智能产业技术创新战略联盟)和鹏城实验室联合了发布《人工智能计算中心发展白皮书2.0——从人工智能计算中心走向人工智能算力网络》,其中明确提到了以“大算力+大数据”使能大模型(多模态多样化的能力一般都由大模型才能更好的实现,或者说多模态的形式表现为大模型)。会上,中国科学院自动化研究所发布了全球首个三模态大模型紫东.太初,这无疑让多模态的发展进入了一个全新的落地阶段。
多模态大模型,正在与人工智能算力网络互相促进,成为彼此的最佳伴行者。
多重因素下,多模态大模型已成大势所趋
随着AI的技术和产业发展逐步走向深入,多模态大模型的趋势十分明朗,这主要表现在三个方面:
首先,是AI自身的能力进化要求。
在单模态领域,例如归属NLP的跨语种翻译这类应用,机器可以说早已超越人类,实现了重要的技术和产业价值,如果要进一步往前走,多模态自然而然就成为AI技术和产业突围的新方向。与此同时,单模态本身也面临“知识冰山”的瓶颈问题,进一步智能化也需要大模型来支撑,例如对“老王去吃食堂”的理解,单纯的文字数据很难让AI辨别“吃食堂”不是把食堂吃掉而是“到食堂吃饭”,但一张场景图片或视频就可以很容易解释清楚并关联起来。
然后,是“数据”供给的要求。
数据是AI发展的根本、是AI的“食物”,在全球范围内,包括中国市场上,互联网的出现帮助AI模型训练的数据量越来越庞大,它们让AI得到了快速的能量补充。
然而,目前互联网音视频数据高速增长,占比超过80%,单一数据类型例如文本只占不多的比例,这使得更丰富的语音、图像、视频等数据并未被充分利用与学习,以多模态的方式将更深度、更广泛地挖掘这些数据的价值,反过来,大量的各种属性的数据投喂也将推动AI摆脱单模态,朝着多模态大模型不断前进。
最后,是产业需求的倒逼。
随着AI逐步落地,产业需求也在往深处走,更多场景应用需要多模态大模型来支撑,例如,跨模态检索、智能问答、文学艺术创作、视频配音、视频摘要等等。
可以说,越是在技术层面将图像、文字、语音相互融合,一个应用在场景中表现的价值就越为明显,也更能让AI的场景应用真正告别常常被诟病的“鸡肋”感。
算力、框架、技术积累三位一体,多模态大模型加速落地
为什么紫东.太初这样的多模态大模型得以实现,原因主要有三大方面,缺一不可:
1、人工智能算力网络成为多模态、大模型的重要推进因素
多模态大模型的一个重要特征,是训练的参数规模呈现指数级的上升。
以往的单模态,单一类型的数据“喂养”帮助AI模型获取知识、迭代能力,相对而言模型本身并不需要太多的参数,就如同小学生不断学习加减乘除一样只要理解基本的数学规则一样。
而当不同模态加入后,一个可以识别图像、文字、语音的通用算法,不仅需要理解单模态的各种数据,还需要理解不同数据之间极端复杂的联系,模型的参数发生膨胀,这就如同专业的大学理工科学习需要综合各种学科知识进行复杂地算一样。
这时候,很显然,算力就成为最基本的支撑,只有超大规模的算力才能支撑大模型的训练,才能让多模态应用有更好的效果。
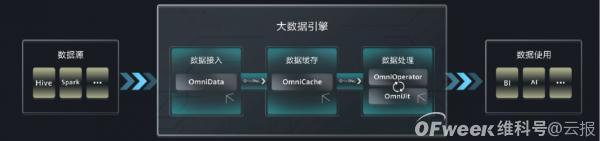
所以,在提供强大集群化算力的各地人工智能计算中心基础上,人工智能算力网络的出现,进一步解决了多模态大模型的算力需求问题,成为重要的推进因素。
事实上,由于大模型的运算很多时候还有波峰波谷的问题(即计算时算力耗费巨大,而不计算时则算力闲置),而人工智能算力网络又能在全国范围内感知、分配、调度人工智能算力,根据各中心算力资源的情况和各地区的需求情况进行算力动态调配,双方的供需关系除了“量”之外在“节奏”上也十分契合。

反过来看,多模态大模型的技术发展以及在产业中的应用,也将推动本身作为各地产业集群推进力量的人工智能算力网络更好地发展,“物尽其用”同时技术不断进步,可见二者是相互促进的关系。
2、昇思MindSpore特性推动开发加速
由于模型参数十分庞大,光有算力支撑还不行,多模态大模型开发所依托的AI框架也需要有承载和利用算力、支持庞大参数的能力,而这方面,过去国内外已有的一些主流开发框架都只支持简单的数据并行,满足不了大模型的需要。
本次在华为全联接2021上发布的多模态大模型紫东.太初,就基于昇思框架训练的,这是业界首个支持全自动并行的框架,全球首个中文预训练大模型鹏程.盘古就出自其手。
昇思框架与多模态大模型相契合的主要技术优势在于,可以在训练过程中自动将模型切分到不同的设备,并高效地利用庞大的计算设备集群来完成并行训练,相当于建立了一套行之有效的中枢指挥系统,将计算任务以同时进行的方式分配下去,再大的训练任务也能有条不紊实现加速,而不是堵塞起来。
其实现过程,是通过多维度自动并行这一独特能力来实现的——通过数据并行、模型并行、Pipeline并行、异构并行、重复计算、高效内存复用及拓扑感知调度,降低通信时间的占用,实现整体迭代时间最小,简单来说就是通过一系列技术创新来让并行更有规模和效率,无需像其他AI框架一样半自动甚至是手动来完成大模型的并行执行开发。
在最新的1.5版本更新中,昇思框架还增加了多种并行调优,支持在大集群下高效训练千亿至万亿参数模型。
3、已有多模态大模型相关经验基础
多模态能力一定建立在单模态能力的基础之上,这是毫无疑问的。此次紫东.太初的开发者即中国科学院自动化研究所,是昇腾AI的重要生态伙伴,在发布紫东.太初之前,中科院自动化研究所就已经在图像、语音、文本三个方面自研了业界领先的模型:

在此基础上,中科院自动化研究所与昇腾AI携手,还实现了一些“前期准备”能力的构建,包括图文跨模态理解与生成性能、视频理解与描述性能的全球领先,这些都成为紫东.太初的重要支撑:

最终可以看到,全球首个三模态大模型紫东.太初应运而生,让多模态从常见的两个模态一跃迈入了三模态时代,不仅可以实现跨模态理解(比如图像识别、语音识别等任务),也能完成跨模态生成(比如从文本生成图像、从图像生成文本、语音生成图像和视频等任务)。
看起来,两个模态与三个模态似乎只有数量的差别,但从技术上,其实现难度或与二维世界到三维世界的跨越类似,需要大量的技术积累与创新。而一旦三模态得以实现,相比较两模态,AI的交互会变得更加自然,能够离强人工智能更近一步。
结语
多模态大模型正在加速赋能产业,在开源开放的大前提下,昇腾AI加持的紫东.太初正在走入智能驾驶、工业质检、影视创作、智慧医疗等应用场景,合作客户包括上汽集团、魏桥创业等知名企业,一幅多模态大模型赋能千行百业的图景正在展开。
从多模态大模型的发展可以看出,未来,随着人工智能算力网络、昇思框架这样的基础软硬件突破性项目的发展,中国的AI将实现从基础技术到产业应用的全面领先,凭借技术和模式创新拥有真正的竞争壁垒。
*本文图片均来源于网络
郑重声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。
相关阅读




猜你喜欢
-
新一代人工智能将给电力调度带来哪些改变
2021-09-28 -
人工智能为什么加深了中美矛盾?
2021-09-26 -
人工神经元新的可能性,或能实现真正的人工智能
2021-09-26 -
小冰第九代正式发布: “人工智能”有了温度
2021-09-23 -
科大讯飞 李心:人工智能帮助电力能源企业实现提质增效降本
2021-09-23 -
「鳍源科技」获数千万元B1轮融资,进行水下人工智能技术布局
2021-09-23 -
强强联手!百度携手中国燃气集团助力能源智能化升级
2021-09-23 -
人工智能上演中美角逐
2021-09-22 -
2021年全球人工智能行业市场规模与投融资现状分析
2021-09-22 -
人工智能计算中心,正在让AI发展进入“乘法”时代
2021-09-18 -
自动驾驶出租车赛道已成一片红海,为何实现商业化落地却异常艰难?
2021-09-18 -
关于2021年度电力人工智能与大数据创新应用成果奖的公示
2021-09-18 -
人工智能降温背后:投资也在降温
2021-09-16 -
三年亏损30亿,第四范式在中国人工智能行业份额如何?
2021-09-14 -
垫底AI四小龙,云从科技是伪人工智能国家队?
2021-09-13